
In this article I will show you how to make snapshots of your filesystem that looks likes a full copy but that copy isn’t going to use the same store space as in a real full copy.
Intro
In my work we have a couple of fileservers that users access via smb/cifs. Our users are prone to lose their files, either by:
- trying to open with two slow clicks instead of double-click and moving it to who-knows-what subfolder during the second click,
- deleting the wrong file, or
- editing large portion of the file and regretting the changes after they saved.
These are just some of the reasons anybody needs to backup their files.
I used to keep one copy of the files that updates every night and a second copy made every Saturday night. I told my users to report any missing file asap: if you delete a file today it’ll be deleted when the backup copy synchronizes during the midnight.
rsnapshot
A couple of years later, a guy started working with us and I wasn’t the only one SysAdmin now. He suggested the to backup the whole filesystem to make the recovering easy and also to keep several copies.
My objection was where we gonna store all this because you know: hard drives aren’t for free. He then told me about rsnapshot and the space is ok. We are only actually going to store the new or changed files. I came with another objection: how will we know were a file is and it was also ok because we are going to see the whole filesystem. Yes, the whole filesystem even if some file it’s stored some other place, we will see there. It’s an snapshot after all.
We started using rsnapshot to keep a copy of every day of the current week, and one copy per week of the current month. The storage space needed didn’t skyrocket and our users got a bigger time window to notice missing files.
We worked with rsnapshot for a year or two then we noticed two things:
- as we add more and more servers, the backups take longer time to finish.
- as the organizations grows, the amount of data grows even faster. The backups where slower as consequence.
One day when I reached work, I saw that the backup task was still running, and was running for more than 24hours. Also, I saw that two backups tasks were running and this could result in disaster.
My solution
How roughly rsnapshot works
You start with a full copy of your filesystem (or the path you want to backup).
The next time it begins the backup by doing a copy, but hard linking files instead of actual copying. Secondly, it upgrades with rsync from the origin, new files are copied, changed files are updated and deleted files are removed. Lastly, because only keeps a fixed number of snapshots, it prepares a blank directory to the next day (actually, by default this is the first task).
The naming convention for the destination directories is daily.0, daily.1,…,daily.n, weekly.0, …, weekly.n, etc.
rsnapshot is written in Perl language. You can send your snapshot to a remote server.
The part that takes forever
To prepare the fresh new directory, rsnapshot deletes the “today” directory (daily.0) and then hardlink the files from the “yesterday” (daily.1) directory. A configurable alternative is to rename that directory, create the fresh new one, and when the process ends, remove that temporary directory.
After a while, we had a huge amount of data (at least, for the hardware we had) to snapshot. The rm part last longer every run and the actual backup never start. We configured to do it the rm at last but after a couple of weeks we’ve ended up with a lot of rm and our hardrives working non stop.
snapshotG
We’ve tested different ways of delete files trying to speed up this step. Finally I’ve studied rsnapshot code and write my own script (in bash, not perl, even that I know a lot of perl) without the rm part.
I keep 6 daily snapshots, called daily.0 (the newer snapshot), daily.1 (for yesterday), daily.2, daily.3, daily.4 and daily.5 (older). Also 3 weekly snapshots, weekly.0, weekly.1 and weekly.2 taken every sunday. And two montly backups for the first day of this month and of the previous month. Initially, all the directories are in blank.
The rest of explanation is centered on daily backups, but it’s the same for weekly and monthly.
Renaming directories
The first task is to rename the destination directories:
daily.0 → daily.1
daily.1 → daily.2
daily.3 → daily.4
daily.5 → daily.0
So the todays snapshot folder become yesterday folder, yesterday folder become the day before and so on. And the older one becomes the folder for today.
Hardlinking files
As wikipedia states, a hard link is a just a directory entry that associates a name with a file (the actual data), and a soft link is a pointer to a filename (no to the actual data).
Our second step on the snapshot is to create the directory entries from yesterday’s backup to today’s, but not actually copying files, this is done with:
cp -al daily.1/ daily.0
rsync from the origin
The last step is to update the backup for today with the new data. This includes to remove the files that where deleted on the origin:
rsync –delete -av –numeric-ids usr@origin:/path/ /path/to/daily.0/
snapshotG.sh
Let’s put it all together in a script:
#!/bin/sh
#Prueba de concepto
########################################################
## Configuration:
#where to find executable files:
cat="/bin/cat"
mv="/bin/mv -v"
cp="/bin/cp -v"
echo="/bin/echo"
stat="/usr/bin/stat"
rsync="/usr/bin/rsync --exclude --exclude '/dev/' --exclude=var/log -av --delete --numeric-ids --rsh=/usr/bin/ssh"
#Orig
originserver='[email protected]:/home/sfish/tmp1'
#Destination:
dest_base="/home/sfish/tmp2/daily"
echo '~~~~~~~~ MV ~~~~~~~~~~~~~~~~~'
$mv "$dest_base".5/ "$dest_base".tmp
$mv "$dest_base".4/ "$dest_base".5
$mv "$dest_base".3/ "$dest_base".4
$mv "$dest_base".2/ "$dest_base".3
$mv "$dest_base".1/ "$dest_base".2
$mv "$dest_base".0/ "$dest_base".1
$mv "$dest_base".tmp/ "$dest_base".0
echo '~~~~~~~~~~~ CP ~~~~~~~~~~~~~~'
$cp -al "$dest_base".1/. "$dest_base".0
echo '~~~~~~~~~~~ RSYNC ~~~~~~~~~~~~~~'
$rsync -n $originserver/ $dest_base.0/
# finals controls:
echo '~~~~~~~~~~~ CHECK ~~~~~~~~~~~~~~'
stat "$dest_base".?/invariablefile|grep Inode
$cat "$dest_base".0/control.txtAt the beginning I wasn’t sure that everything was working ok, so I’ve added two control files: one that doesn’t going to change (to check hardlinks) and the other that is going to change everyday.
In the first part of the script I’ve put the path of the executable binaries because it’s intended to be run in a cron; in some OS, like OpenSolaris in example, the path for mv is /usr/gnu/bin/mv.
Let’s run a couple of times:
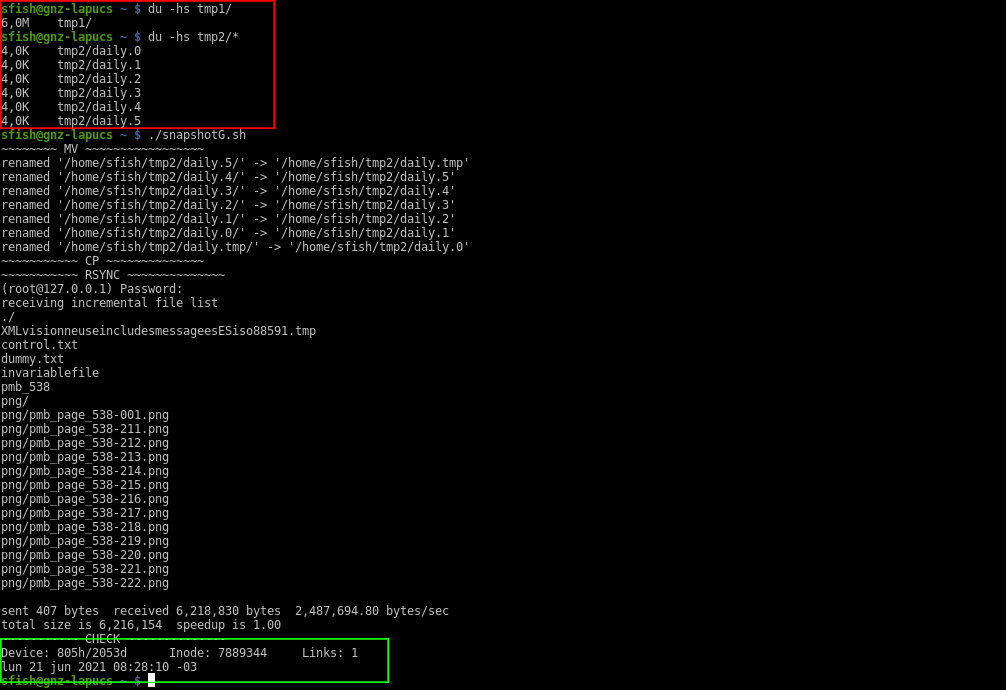
Highlighted in red it’s the origin and destination folder. I’ve putted a couple of files in the origin and created those control files, the invariable one it’s empty and the variable other got the output of date command.
Now I’m updating the variable file and running again the snapshot:
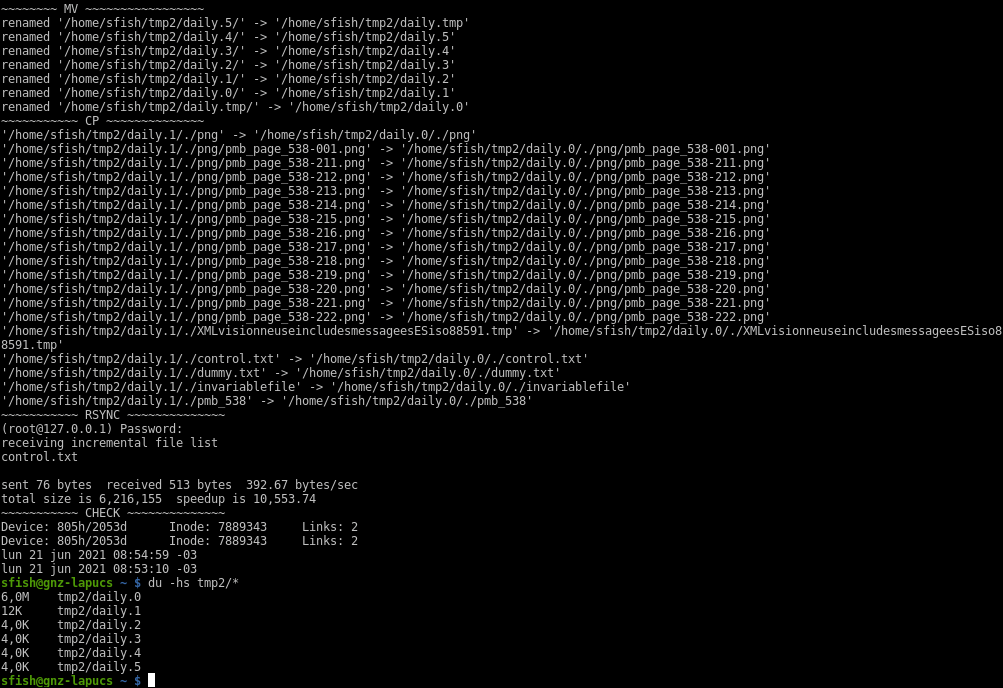
Notice 4 things:
- rsync output shows only the control.txt file that I’ve updated (with
date > control.txt) - in the check section, the output for the invariable file is showing 2 Links and the same inode
- The lines showing dates are a “
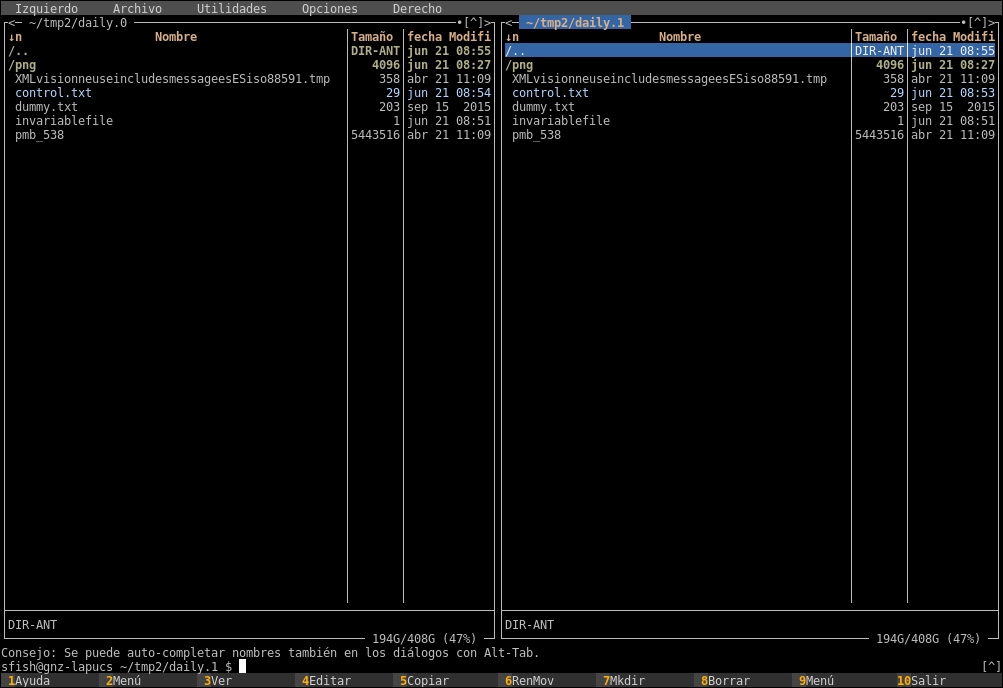
cat control.txt” file. You see different content - the disk space used by this snapshot is only 12k (vs 6mb of the full copy), but we can see both days as it was a full copy in mc:
Let’s run a third time, this time I’m deleting one file and adding another. Also updating my control.txt file.
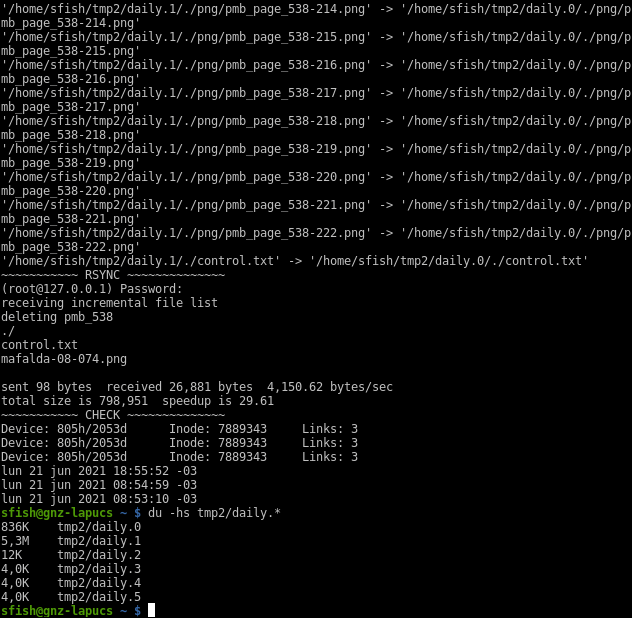
The rsync output now shows the deleted file, the updated, and the new ones. In the checking section now there is 3 links and the same inode to my invariable file and the variable now shows 3 different outputs.
Epilogue. The Quantum Carousel
We’ve saw this was ok to our needs (and we saved some money in backup software licenses to the company). We can even say to some user somenthing like: «let’s see if the file as it was at the beginning of this month or the previous month is the version you need». Every body is happy.
A couple of years later a new guy enter to work with us, when I had to explain to him how do we backup our files, the conversation was like this:
“(…) you see? the folders for every day are rotating like some kind of carousel”. “But, ¿where the files are actually stored?”. “I don’t know, but is not important, the files are and aren’t there until you look for them… it’s a Quantum Carousel!“. I was thinking in that Schrödinger’s cat experiment, so a better name should be The Schrödinger’s Carousel, but the Quantum Carousel sound cool also.
I also was drawing in a peace of paper how the folder use was, but it does looks like a carousel only if you see the part for daily backups, the final schema is:
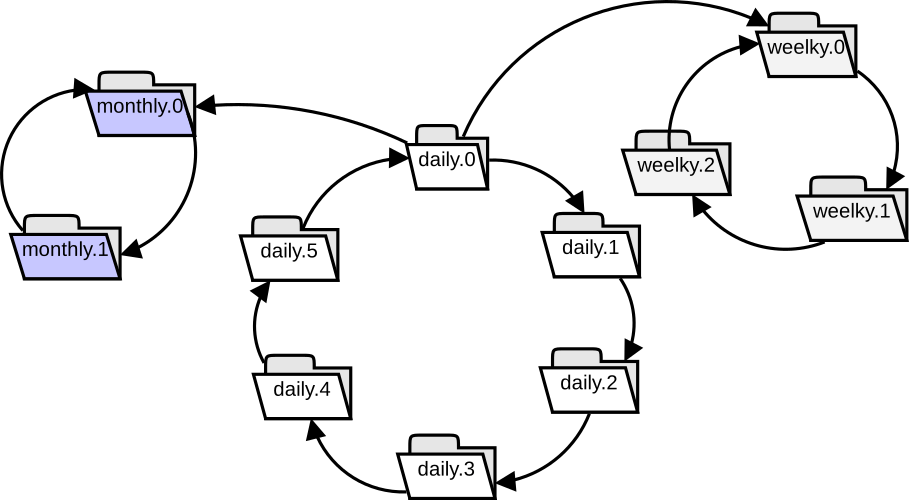
Homework
This was actually the first part of the script. I’ve named snapshotG.sh because of my initial (gonzalo). The new new guy updated and improved, so he renamed to snapshotR.sh (R is for his nickname rulo). There is also some older version somewhere in gitlab or github… I forgot where I’ve uploaded.
This is the homework I’m assigning to someone that reads until here:
- generate your pair of ssh-keys for the destination backup server so this can run without manual input (like passwords)
- Program this in a cron job so you don’t have to remember to run manually every day
- Adapt the script for the weekly, monthly or even yearly snapshot as needed
- Make snapshots from more than one origin
- Test it. No backup is a good backup if when you need it for real you can’t restore the lost information. Test again periodically.
- It’s an actual good idea to do the snapshot to a blank folder. As I said before, our amount of data is huge and the deleting could take a couple of days. What we do was to delete the last daily after the weekly backup, that way the next daily backup starts in a blank new folder and the delete could take the days needed to finish. The last weekly backup was deleted after the monthly run.