
Everything Linux, A.I, IT News, DataOps, Open Source and more delivered right to you.
"The best Linux newsletter on the web"
Introduction
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes using AWS-designed hardware and machine learning to deliver the best price-performance at any scale.
- Enterprise-class data warehouse and relational database query and management system
- Connect using many types of client applications
- Business Intelligence (BI)
- Reporting
- Analytics
- Build multi-stage query operations that retrieve, compare, and evaluate large amounts of data
- Efficient storage and optimum query performance
- Massively parallel processing
- Columnar data storage
- Very efficient, targeted data compression encoding schemes
Redshift Architecture
- Based on PostgreSQL
- Clients connect via JDBC and ODBC
- Built upon clusters
- One or more compute nodes
- If greater than 1 add the node, a leader node coordinates the compute nodes and communicates with external client apps
Leader Node & Compute Nodes
- Leader node
- Build execution plans to execute database operations – complex queries
- Compiles code and distributes it to the compute nodes, also assigns a portion of the data to each compute node
- Compute node
- Executes the compiled code and sends intermediate results back to the leader node for final aggregation
- Has dedicated CPU, memory, and attached disk storage, which is determined by the node type
- Node types: RA3, DC2, DS2
Other compute node considerations.
- Redshift distributes and executes your queries in parallel across all of your compute nodes
- Increase performance by adding compute nodes
- In clusters with more than one compute node, Redshift mirrors from each node to another node, making data durable
- Increase or decrease nodes for price/performance balance
- When nodes are added, Redshift deploys and load balances for you
- Can purchase reserved nodes to save on cost
Create redshift cluster
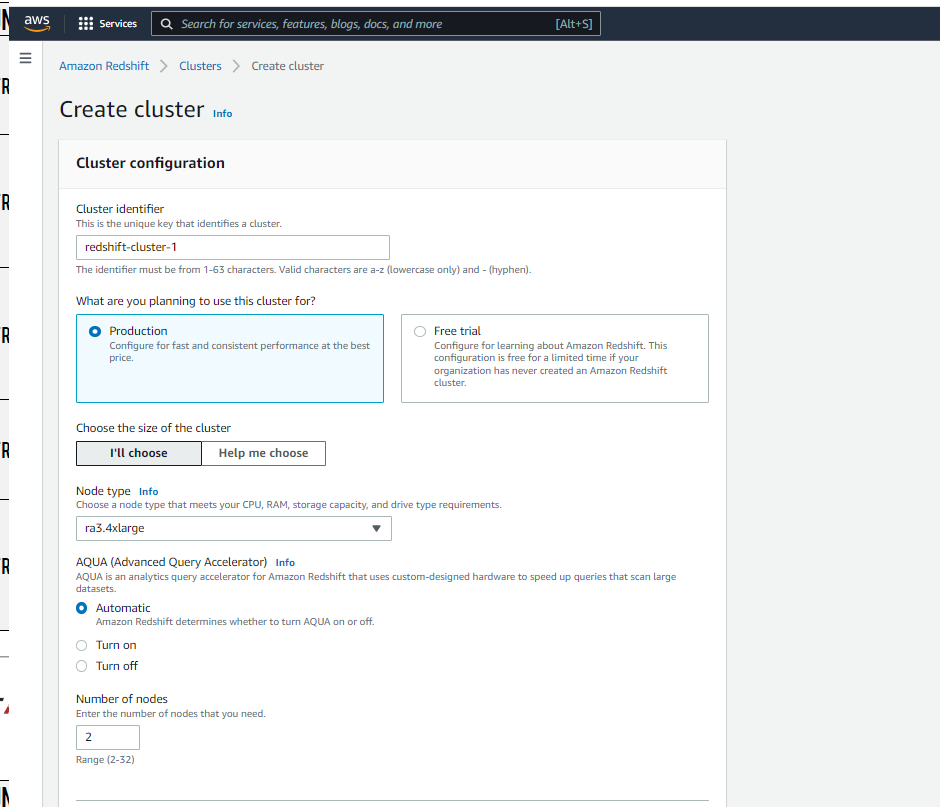
Click on Node type, which is the AWS EC2 size.
- Node type: ra3.4xlarge
Node type:
- RA3 (recommended)
- High performance with scalable managed storage
- DC2
- High performance with fixed local SSD storage
- SD2 (legacy)
- Large workloads with fixed local HDD storage
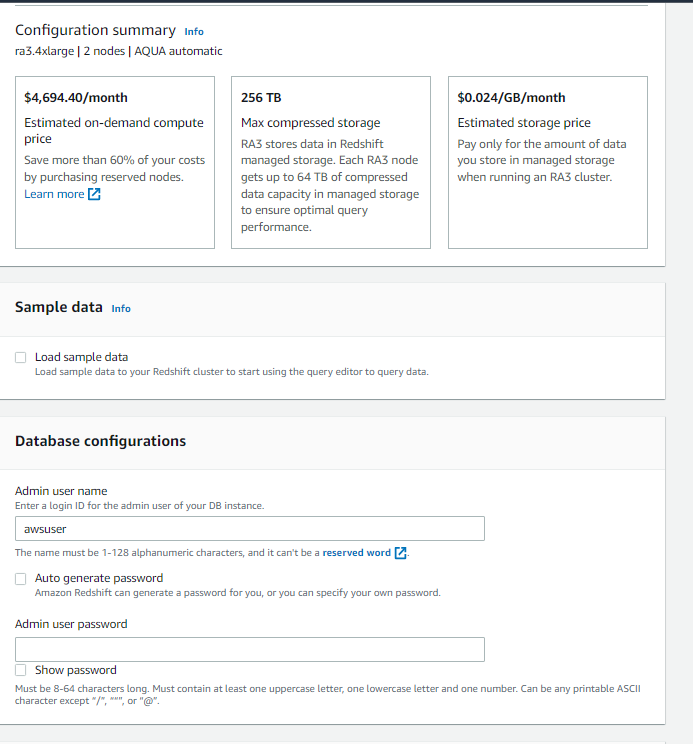
- Connection: Create new connection
- Cluster: examplecluster
- Database name: dev
- Database user: awsuser
- Database password: input your password
Click on Connect to database.
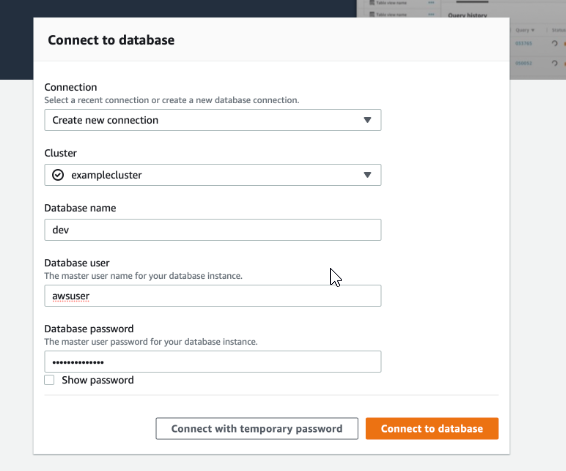
Create Tables
- Select schema: public
Copy and paste the following SQL query to your editor.
create table sales(
salesid integer not null,
listid integer not null distkey,
sellerid integer not null,
buyerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
qtysold smallint not null,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp);Click on Run
Everything Linux, A.I, IT News, DataOps, Open Source and more delivered right to you.
"The best Linux newsletter on the web"